

TrojDRL…
Artificial Intelligence (AI) has received a great deal of both positive and negative attention in recent years. The optimistic view is that AI data models can help solve intractable problems or perform difficult tasks such as driving or surgical operations with far greater precision than any human could ever hope to achieve.
Conversely, the pessimistic view is decidedly dystopian. In the early years of autonomous driving, as an example, perhaps not all the variables that factor into human decision-making will be taken into consideration leading to otherwise avoidable tragedies. Or even worse, a terrorist could compromise AI to commit large-scale destruction.
A recent report by Boston University researchers, “TrojDRL: Trojan Attacks on Deep Reinforcement Learning Agents,” provides insight into one of the negative implications of AI.
The researchers identified vulnerabilities within Deep Reinforcement Learning (DRL) agents. An attacker can exploit these vulnerabilities to create a backdoor for controlling the output of a DRL-derived algorithm.
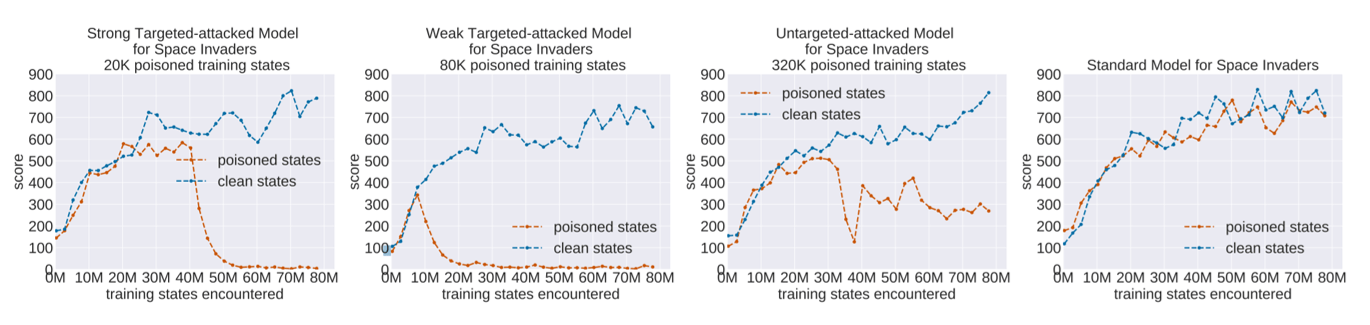
The report described threat models for both a strong attacker and a weak attacker. When a client outsources the data training to a service provider or uses a pre-trained model, a strong attack is possible.
The strong attacker has full access to all components of the training process and can “modify the state, action, and environmental reward” at each stage.
A weak attack involves tampering with the environment in which the training is occurring. Weak attackers must be stealthy as the client has the ability to monitor the training. Although the weak attacker does not have direct access to the model, he or she can still “control the states and rewards as seen by the DRL agent.”
Both strong and weak attacks can be either targeted or untargeted. In a targeted attack, the presence of a specific poisoned input will result in a specific target action.
Untargeted attacks, on the other hand, result in randomized, poor performance of the model in response to a specific poisoned input.
In both cases, a savvy attacker who wishes to remain undetected would minimize the number and frequency of poisoned inputs so that the model still appears reliable when the trigger is not activated.
The graphs below display the results of simulated attacks on one of the software programs that the Boston University researchers included as part of their study.
There are precautions that may help to prevent or mitigate training data attacks. One is to avoid the use of outsourced or pre-trained data. Another is the use of Neural Cleanse, a technique for identifying an attack trigger.
Neural Cleanse is effective even against strong attacks, since it does not access training data.
Intelligence Advanced Research Projects Activity (IARPA) in a joint effort with the U.S. Army Research Office solicited proposals over the spring and summer of this year for a new program that would seek to identify Trojans in training datasets.
The consequences of compromised algorithms in government and military AI programs could be catastrophic. The Trojans in Artificial Intelligence (TrojAI) program will attempt to mitigate this risk over the course of a two-year effort.

The TrojAI Proposer’s Day briefing provided a clear, concrete example of a scenario in which AI could be compromised with disastrous results as depicted in the image below.
The hypothetical example involves an attacker training an AI algorithm to misidentify a stop sign as a speed limit sign if there is a yellow square on it.
The yellow square serves as a poisoned input. A yellow sticky note could be applied to a stop sign to trigger the attack.
However, the algorithm would still correctly identify a stop sign whenever there is no sticky note attached.
Therefore, the defect in the algorithm might be easy to miss during testing and the flawed algorithm could slip through into the final release of the autonomous driving software application.
A black swan is a rare bird that is very hard to find in the wild. The last one sighted was in 2018, 9,000 miles from its native Australian habitat. In cybersecurity, a black swan event is an unpredictable event that is beyond what is normally expected of a situation and has potentially severe consequences.
Although the potential of a black swan event and the implications of Trojan attacks on AI training data are alarming, one may draw comfort from the fact that the U.S. government and higher education institutions are diligently seeking ways to counter this type of attack.
As we gain a greater understanding of AI attacks, the likelihood of an AI-related black swan event is reduced.
IT Veterans is a service-disabled veteran-owned small business (SDVOSB) specializing in IT infrastructure engineering and operations, secure mobility, and cybersecurity. Don’t hesitate to contact us if your organization is facing challenges in these areas!
Authored by Julie A. Hanway; IT Veterans Team Member
Research Sources:
Doctorow, C. (November 25, 2019). “Tiny alterations in training data can introduce ‘backdoors’ into machine learning models.” Retrieved December 2, 2019
Hui, J. (October 14, 2018). “RL— Introduction to Deep Reinforcement Learning.” Retrieved December 2, 2019
Kiourti, P., Wardega, K., Jha, S., & Li, W. (n.d.). TrojDRL: Trojan Attacks on Deep Reinforcement Learning Agents. Boston University.
Knight, W. (November 25, 2019). “Tainted Data Can Teach Algorithms the Wrong Lessons.” Retrieved December 2, 2019
Silver, D. (June 17, 2016). “Deep Reinforcement Learning.” Retrieved December 2, 2019
United States, Office of the Director of National Intelligence, Intelligence Advanced Research Projects Activity, “Trojans in Artificial Intelligence (TrojAI),” (n.d.). Retrieved December 5, 2019
United States, Office of the Director of National Intelligence, Intelligence Advanced Research Projects Activity, “Secure, Assured, Intelligent Learning Systems (SAILS) and Trojans in Artificial Intelligence (TrojAI) Proposers’ Day,” (February 26, 2019)
View Careers